
La Révolution industrielle a remplacé les muscles par des machines et a changé de façon permanente le fonctionnement du monde. La Révolution de l’IA remplace le travail cognitif par des algorithmes et avance dix fois plus vite.
Alors que les grands modèles de langage (LLM) comme ChatGPT, Gemini, Claude sont utiles pour le contenu et le remue-méninges – ils fonctionnent sur la probabilité des mots plutôt que sur la logique mathématique ou réglementaire. Dans un secteur où une « bonne supposition » est un risque, environ 15 à 19% des réponses de l’IA, en droit et en santé, contiennent des informations fabriquées ou des « hallucinations ». Dans l’industrie alimentaire, une étiquette nutritionnelle « presque précise » est le choix le plus risqué qu’une entreprise alimentaire puisse faire, ce qui entraîne des rappels et des lettres d’avertissement de la FDA (et d’autres organismes de réglementation).
Cet article offre une analyse unique et approfondie de la façon dont les modèles d’IA se comparent à un générateur d’étiquettes nutritionnelles dédié comme Food Label Maker. Nous explorerons les 6 risques critiques auxquels les entreprises alimentaires peuvent faire face lorsqu’elles s’appuient sur l’IA comme générateur d’étiquettes nutritionnelles, et pourquoi les logiciels réglementaires spécialisés sont la seule façon d’assurer une conformité à 100% sur tous les marchés.
Tu veux commencer? Créez une étiquette gratuite avec notre générateur d’étiquettes de renseignements nutritionnels.
TL; DR — Points clés
- Comment fonctionnent les LLM : ChatGPT, Claude et Gemini sont construits sur une architecture de prédiction de séquences, ce qui signifie que chaque sortie est une estimation statistique basée sur des données d’entraînement, et non le résultat d’une règle fixe.
- Données à jour : La plupart des LLM ont des seuils de connaissance, ce qui les rend inconscients des mandats actuels tels que les exigences canadiennes sur le devant de l’emballage 2025/2026 et les règles d’arrondi mises à jour de la FDA.
- Formatage des étiquettes : Parce que l’IA estime plutôt que d’imposer, elle ne peut pas produire de façon fiable les tailles de polices pixel-parfaites, les poids des bordures et les mises en page bilingues exigés par la FDA et la CFIA.
- Gestion des recettes : L’IA fonctionne dans des sessions de clavardage isolées sans mémoire persistante, ce qui rend la gestion centralisée des ingrédients et les mises à jour inter-recettes structurellement impossibles.
- Traçabilité des aliments : L’IA génère un texte statique sans lien avec les fournisseurs, sans historique de versions et sans trace d’audit, aucun de ces éléments ne répondant aux normes documentaires attendues lors des examens réglementaires.
- Sécurité des données : Le contenu saisi dans les comptes standards d’IA des consommateurs peut être utilisé pour entraîner de futurs modèles. Food Label Maker fonctionne sur une infrastructure auditée SOC 2 Type II où les données de recettes demeurent privées.
| Caractéristiques | ChatGPT / Gemini / Claude | Fabricant d’étiquettes alimentaires |
| Monnaie réglementaire | Limite de connaissance Ignorant les obligations de 2025/2026 | Synchronisé en direct avec la FDA, l’ACIA, l’UE et d’autres réglementations mondiales sur l’étiquetage alimentaire |
| Mathématiques du rendement et de l’humidité | Probabilistique Peut être ignoré la perte d’humidité sauf indication explicite de l’utilisateur | Déterministe |
| Gestion des recettes | Fils de discussion fragmentés Aucune persistance | Tableau de bord centralisé Synchronisation globale des ingrédients |
| Formatage des étiquettes | Variations incohérentes selon la demande | Modèles d’étiquetage alimentaire natifs de la FDA et mondiaux. Sortie avec précision pixel |
| Traçabilité alimentaire | Texte statique Aucune trace d’audit | Fiches techniques liées Historique complet des changements |
| Sécurité des données | Modèles publics Les données peuvent entraîner des modèles futurs | SOC 2 Type II Conformité Infrastructure privée |
Comment fonctionnent réellement des modèles d’IA comme ChatGPT, Claude et Gemini
Avant d’entrer dans les détails de ce que l’IA peut ou ne peut pas faire avec les étiquettes nutritionnelles, il est utile de comprendre ce que font réellement les modèles LLM (comme ChatGPT, Claude, Gemini, etc.) lorsqu’on leur demande une tâche.
Tous les outils modernes d’IA générative disponibles aujourd’hui reposent sur une architecture fondamentale appelée le Transformer.
Définition d’un modèle de transformateur IA :
Une architecture d’apprentissage profond qui fonctionne principalement comme un moteur de prédiction séquentielle. Les modèles Transformer génératifs de texte fonctionnent selon le principe de la prédiction du jeton suivant : étant donné une invite textuelle de l’utilisateur, quel est le jeton suivant le plus probable (un mot ou une partie d’un mot) qui suivra cette entrée?
En ce qui concerne les invites, cela signifie : l’IA ne lit pas les instructions et ne les exécute pas comme le fait le logiciel. Il lit les instructions et produit la réponse la plus probable statistiquement basée sur tout ce sur quoi il a été entraîné et toutes les informations reçues auparavant. Il n’y a pas de règles codées en dessous, seulement des motifs et des probabilités. Pour la plupart des tâches, cela fonctionne assez bien pour donner l’impression de suivre les règles. Mais demandez-lui de produire quelque chose qui doit être exactement, légalement et à répétition (comme une étiquette de faits nutritionnels) – l’écart entre prédire ce qui semble juste et appliquer une règle sans exception devient un problème sérieux.
Utilisation de l’IA pour la conformité réglementaire en temps réel
La plupart des grands modèles de langage ont un seuil de connaissance qui les fait ignorer les dernières règles d’arrondissement de la FDA, l’obligation d’étiquetage du Front-of-Package (FOP) du Canada pour 2025/2026 et d’autres changements réglementaires importants. Un générateur d’étiquettes nutritionnelles avec synchronisation réglementaire en temps réel élimine complètement ce risque.
L’IA connaît-elle les règles réglementaires en nutrition mises à jour?
La plupart des LLM ont des seuils de connaissances; Ils ne sont pas intrinsèquement conscients des changements réglementaires les plus récents dans l’étiquetage nutritionnel. Par exemple:
- OpenAI (GPT-4o) : La limite de connaissances est en octobre 2023
- Anthropic (Claude) : La date limite de connaissances est en août 2025
- Gemini (Google) : Il n’existe pas de seuil clair de connaissance pour les modèles actuels, ce qui rend l’utilisation des modèles Gemini pour des connaissances à jour plus peu fiable
Même si les LLM parcourent le web pour trouver les dernières informations, tout ce qu’ils font, c’est résumer et récupérer le texte. Un LLM pourrait trouver un article de presse sur le changement et la logique mise à jour, mais il y a de fortes chances que l’ancienne logique soit appliquée lors de la génération d’une étiquette. Le « raisonnement » du modèle sur la façon de calculer et de formater les données nutritionnelles repose sur la façon dont elles ont été entraînées et non mises à jour en temps réel. La dernière conclusion est que l’IA ne peut pas appliquer de façon fiable une nouvelle logique réglementaire à vos calculs d’étiquette, même lorsqu’elle sait que la règle existe.
Mises à jour automatisées de conformité dans le fabricant d’étiquettes alimentaires
En matière de conformité réglementaire à jour, la différence fondamentale entre l’IA et un générateur d’étiquettes nutritionnelles comme Food Label Maker est que le logiciel est constamment mis à jour avec les règlements récents et bénéficie d’une intervention humaine pour garantir que chaque règle est appliquée correctement.
Derrière chaque mise à jour de l’étiquetage nutritionnel se trouve une équipe qui surveille activement les annonces réglementaires de la FDA, de l’ACIA, de la FSA et d’autres organismes de réglementation. Quand une réglementation change, nos développeurs ne se contentent pas de la lire – ils traduisent le langage juridique en logique de calcul exacte, la testent avec de vraies données produit, et poussent la mise à jour sur chaque compte utilisateur. Il n’y a aucune ambiguïté, aucune interprétation d’un modèle de langage qui pourrait réussir à moitié juste. Un expert humain en réglementation vérifie le changement, un développeur l’encode, et l’assurance qualité confirme que le résultat correspond à ce que la réglementation exige.
C’est quelque chose que l’IA ne peut fondamentalement pas reproduire. Un LLM n’a pas d’équipe derrière lui pour surveiller spécifiquement les mises à jour réglementaires de l’étiquetage nutritionnel. Il n’y a aucun processus d’assurance qualité pour la conformité alimentaire. Avec Food Label Maker, il y a une équipe réglementaire dédiée qui s’assure que la mise à jour est en ligne avant toute date d’application.
Découvrez comment FoodLabelMaker peut vous aider
Pourquoi l’IA a du mal à calculer la perte d’humidité et le rendement
Les LLM tiennent compte de la perte d’humidité et du rendement si l’utilisateur le demande explicitement de le faire. Si un utilisateur ne sait pas qu’il doit demander, il est fort probable que l’IA ne saura pas qu’elle doit le calculer, créant ainsi une étiquette nutritionnelle basée sur le poids des ingrédients bruts plutôt que sur ce que le consommateur mange réellement.
Comment l’IA hallucine-t-elle les calculs de rendement nutritionnel?
Lorsqu’un produit est cuit, l’eau s’évapore et le produit final pèse moins que la somme de ses ingrédients bruts. Ce changement de poids affecte directement la densité des nutriments comme les calories, le sodium et les gras par portion, car ils augmentent tous par rapport au poids fini plus petit. Les LLM n’en ont probablement aucune connaissance à moins d’y être explicitement sollicités.
Cette limitation est appuyée par la recherche. Une étude évaluant trois grands modèles de langage pour l’estimation du contenu nutritionnel à partir d’images alimentaires a révélé que les LLM ont du mal à estimer avec précision le poids alimentaire, la teneur énergétique et la composition des macronutriments – même à partir de photographies standardisées. La perte d’humidité est fondamentalement une tâche d’estimation du poids; Si l’IA ne peut pas estimer de façon fiable le poids des ingrédients dès le départ, il est très peu probable qu’elle puisse calculer de façon fiable le rendement obtenu après la cuisson
Cela place entièrement le fardeau sur l’utilisateur. Obtenir une étiquette précise de l’IA nécessite de savoir spécifier le pourcentage de rendement, de comprendre comment la perte d’humidité affecte la densité des nutriments, d’inciter l’IA à recalculer, puis de vérifier manuellement le résultat. Oublier l’une de ces étapes produit une étiquette non conforme.
Comment un générateur d’étiquettes de faits nutritionnels gère avec précision les calculs de rendement
Food Label Maker prend en charge le fardeau des calculs complexes de perte d’humidité. Le logiciel demande le rendement comme une étape standard dans le flux de recette, et non comme une réflexion après coup qui dépend des connaissances en science alimentaire de l’utilisateur.
Une fois saisi, la densité des nutriments est calculée en fonction du poids du produit fini à l’aide de formules déterministes, et non de prédiction probabiliste en texte. Cela signifie qu’un utilisateur débutant sans expérience en étiquetage obtient le même résultat mathématiquement précis qu’un scientifique alimentaire expérimenté. Le logiciel ne saute pas d’étapes, n’a pas besoin qu’on lui rappelle, et ne revient pas silencieusement aux poids des ingrédients bruts lorsque les données de rendement manquent. Un générateur d’étiquettes nutritionnelles spécialement conçu considère le rendement comme non négociable.
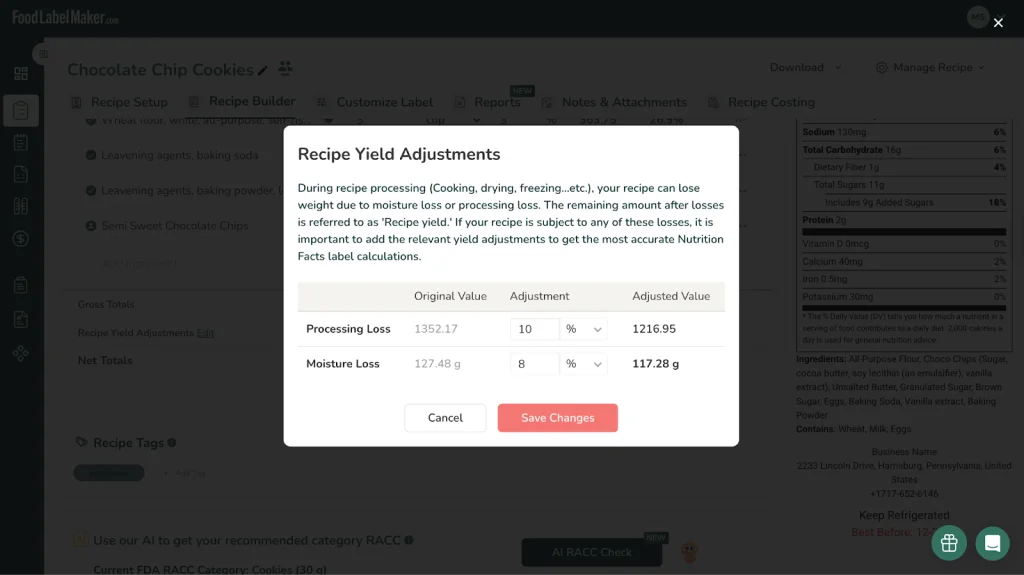
IA vs. un centre centralisé de gestion de recettes
Les fils de discussion IA sont fragmentés par conception. Chaque changement d’ingrédient nécessite une remise en question à partir de zéro. Un générateur centralisé d’étiquettes nutritionnelles maintient une source unique de vérité pour toutes les recettes, ingrédients et données des fournisseurs.
Le risque de gérer des recettes dans des discussions IA déconnectées
Les LLM fonctionnent dans des fils de discussion isolés sans mémoire persistante entre les sessions. Lorsqu’une entreprise alimentaire gère des dizaines ou des centaines de recettes et d’ingrédients, cela devient un problème opérationnel sérieux. Si un fournisseur modifie le profil nutritionnel d’un ingrédient, par exemple un fournisseur de farine change de moulin, chaque recette utilisant cet ingrédient doit être recalculée. Avec l’IA, cela signifie relancer manuellement chaque recette individuellement, en espérant que le modèle applique les valeurs mises à jour de façon cohérente, et en vérifiant le résultat à chaque fois.
Il n’y a pas de base de données centrale reliant plusieurs conversations, ce qui signifie que chaque fil de discussion existe indépendamment, avec peu de lien avec ce qui a été calculé lors d’une autre session. Une mise à jour d’ingrédient qui devrait prendre quelques secondes devient plutôt un processus fastidieux et sujet aux erreurs consistant à copier des données entre les threads et à faire confiance à l’IA pour interpréter chaque invite de la même façon deux fois – un processus à haut risque.
Pour les entreprises opérant à plus grande échelle, cette fragmentation introduit un risque réel de conformité. Un recalcul manqué même sur un seul aliment signifie qu’une étiquette avec des données nutritionnelles obsolètes risque d’être commercialisée, une recette pour les rappels.
Utilisation d’une base de données centralisée pour la synchronisation globale des ingrédients
En revanche, un générateur d’étiquettes de faits nutritionnels est une base de données centralisée où les recettes font partie d’un système interconnecté plutôt que des fichiers texte isolés. Cette « source unique de vérité » permet aux utilisateurs de stocker les ingrédients dans une bibliothèque maîtresse. Si un fournisseur met à jour une fiche technique, les données sont modifiées une fois dans le tableau de bord, et la mise à jour se propage automatiquement à chaque recette liée. Cela élimine les erreurs manuelles de re-invite et de « copier-coller » inhérentes aux flux de travail de l’IA. De plus, le logiciel offre une intelligence instantanée entre recettes, permettant à une entreprise de fouiller l’ensemble de sa gamme de produits à la recherche d’allergènes ou d’ingrédients spécifiques en quelques secondes. C’est une tâche presque impossible pour un LLM qui ne peut pas effectuer une recherche globale à travers des sessions de clavardage indépendantes et déconnectées.
La lutte de l’IA avec les formats d’étiquettes conformes
Les étiquettes nutritionnelles générées par l’IA sont très susceptibles de produire un formatage incohérent qui varie selon chaque prompt. La FDA et d’autres organismes de réglementation ont des exigences strictes en matière de visibilité qu’un générateur de texte probabiliste ne peut pas reproduire de manière fiable. Un générateur dédié d’étiquettes nutritionnelles utilise des modèles préassemblés et verrouillés par la réglementation pour créer des étiquettes nutritionnelles conformes.
Pourquoi l’IA ne peut pas générer d’étiquettes nutritionnelles prêtes à l’impression
La FDA et d’autres organismes de réglementation ont des exigences strictes sur les étiquettes nutritionnelles, pas des suggestions. Des éléments visuels tels que : les tailles minimales de police, les poids des bordures, l’espacement des lignes et la disposition bilingue des colonnes doivent être exacts. C’est là que la nature probabiliste de l’IA devient une responsabilité directe en conformité.
Avec les moteurs de prédiction de séquences des LLM, ils estiment la sortie la plus probable statistiquement basée sur les données d’entraînement plutôt que d’appliquer des règles.
Des études montrent que les modèles d’IA générative ont du mal avec des règles précises et non négociables, qui correspondent exactement au type de précision exigé par la FDA, l’ACIA, la FSA et d’autres règles de formatage. Des recherches plus approfondies montrent également que les modèles d’IA performent moins bien sur les détails visuels détaillés, en particulier les éléments à petite échelle et les relations spatiales précises. Sur une étiquette alimentaire, cela signifie des poids de traits erronés, des polices qui sont en dessous de la taille de points requise à la résolution d’impression, ou des colonnes bilingues qui ne respectent pas les tolérances d’espacement exactes. Une autre étude très importante a approfondi la façon dont la régénération ou l’ajustement d’un élément pouvait entraîner un déplacement silencieux d’en d’autres. Ceci est identifié comme une incohérence d’instructions, où le modèle d’IA pourrait discrètement passer outre des instructions explicites en hallucinant.
Imaginez demander deux fois une police de 6 points et obtenir deux résultats différents – c’est là que les détails pour générer des étiquettes nutritionnelles conformes comptent vraiment.
Comment le fabricant d’étiquettes alimentaires produit des étiquettes nutritionnelles prêtes à être auditées
Le logiciel Food Label Maker est construit autour de modèles pré-codés et verrouillés par la réglementation, plutôt que d’estimations IA à partir de données d’entraînement. Cela signifie que chaque élément visuel d’une étiquette nutritionnelle est régi par des règles exactes, et non par des prédictions statistiques. Chaque exigence de format, telles que : tailles de police, poids des bordures, interligne et disposition des colonnes, est appliquée à la spécification exacte requise par l’organisme de réglementation compétent. Les utilisateurs peuvent passer d’un à l’autre Formats verticaux, tabulaires, simplifiés et à double colonne FDA en un seul clic, avec des règles d’arrondi correctes appliquées instantanément à chaque fois.
Pour les entreprises qui vendent sur plusieurs marchés, Food Label Maker gère la conformité multi-régions sans aucune reconfiguration manuelle. Alternez entre la FDA, l’ACIA, l’UE et d’autres formats régionaux et le logiciel applique automatiquement les valeurs quotidiennes correctes, les exigences bilingues et les normes de mise en forme visuelle pour ce marché. Ce n’est pas une tâche qui nécessite une nouvelle invitation, c’est une règle que le logiciel applique à chaque fois.
Les étiquettes sont également exportées sous forme de fichiers prêts à l’impression haute résolution (PDF, SVG, BMP ou PNG) à la résolution requise pour la production d’emballage
C’est la différence fondamentale : l’IA produit une étiquette qui semble conforme. Le fabricant d’étiquettes alimentaires produit une étiquette conforme et peut le prouver.
Pourquoi l’IA est peu fiable pour la traçabilité alimentaire
La traçabilité alimentaire nécessite des données vérifiées et liées — et non du texte statique généré à partir d’une invite. L’IA ne peut pas connecter les fiches techniques des fournisseurs à des recettes spécifiques ni maintenir une trace d’audit des changements d’ingrédients. Un générateur d’étiquettes nutritionnelles comme Food Label Maker relie les rapports de traçabilité directement à vos recettes et aux données des fournisseurs.
Pourquoi l’IA ne peut pas produire un enregistrement vérifié de traçabilité alimentaire
La traçabilité alimentaire nécessite un enregistrement vérifiable et connecté de chaque ingrédient, de sa source et de chaque modification apportée au fil du temps. L’IA est incapable de produire ce niveau de détail et de responsabilité. Ce qu’il produit, c’est un texte statique, une réponse générée à partir d’une invite, sans lien avec les fournisseurs, sans mémoire des sessions précédentes, et sans journal de ce qui a changé ou quand.
Lorsque les changements d’ingrédients sont gérés via des discussions IA, aucun enregistrement de ces changements n’est conservé entre les sessions. Il n’y a pas d’historique des versions, pas de lien vers les valeurs précédentes, et aucun moyen de vérifier quelle itération d’une recette a produit une étiquette nutritionnelle donnée. Cet écart devient important lors d’un audit des fournisseurs ou d’un examen réglementaire.
Fiches techniques intégrées et historique d’audit dans le fabricant d’étiquettes alimentaires
Food Label Maker aborde la traçabilité comme un système connecté. Lorsqu’un ingrédient personnalisé est ajouté à la plateforme, la fiche technique d’un fournisseur peut être téléchargée directement dans l’enregistrement des ingrédients. L’outil d’analyse des fiches techniques IA du Food Label Maker lit le document et remplit automatiquement la répartition nutritionnelle complète (calories, macronutriments, micronutriments, vitamines, minéraux et acides aminés) aux côtés du nom et du code du fournisseur, afin que l’origine de chaque ingrédient soit rattachée à son dossier depuis le point d’entrée.
Cet ingrédient est ensuite lié à toutes les recettes qui l’utilisent. Lorsqu’une valeur est mise à jour, le changement se reflète automatiquement dans toutes les recettes associées, sans qu’aucune saisie manuelle ne soit nécessaire.
Chaque action effectuée sur la plateforme est consignée dans le journal de l’historique d’activité, enregistrant le nom de l’utilisateur, la date, le module affecté, ainsi qu’une description précise de ce qui a changé – si un ingrédient a été ajouté, qu’une valeur ait été mise à jour ou qu’un coût ait été modifié. Le résultat est un enregistrement horodaté, attribué par l’utilisateur, de chaque modification apportée à chaque recette et ingrédient du système, ce qui est le type de documentation que les audits des fournisseurs et les examens réglementaires exigent généralement.
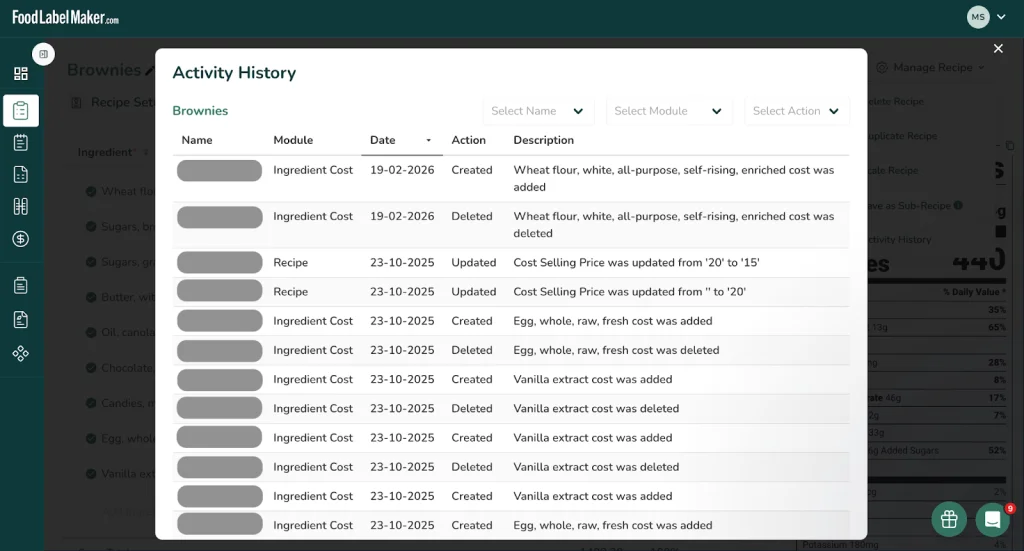
Haute sécurité – Pourquoi SOC 2 est meilleur que l’IA publique
Lorsque vous collez des recettes propriétaires dans ChatGPT, Gemini ou Claude, ces données peuvent être utilisées pour entraîner de futurs modèles, sauf si vous avez une entente d’entreprise. Un générateur d’étiquettes nutritionnelles auditées SOC Type II garde vos formulations privées et ne les expose jamais à des formations tierces.
Que se passe-t-il avec les données de recettes lorsqu’on utilise un outil d’IA public
Lorsque des recettes propriétaires sont saisies dans un outil d’IA public comme ChatGPT, Gemini ou Claude, ce contenu est collecté et stocké par la plateforme. Selon les politiques de confidentialité publiées par OpenAI, Google et Anthropic, le contenu soumis via des comptes consommateurs standards peut être utilisé pour améliorer et entraîner leurs modèles — à moins que l’utilisateur ne se retire activement ou détienne un accord de niveau entreprise.
Pour les entreprises alimentaires, cela crée un risque évident pour la propriété intellectuelle. Une formulation propriétaire, un ratio d’ingrédients personnalisé ou un processus de fabrication unique entré dans une invite de discussion n’est plus exclusivement privé. Même avec les paramètres de désinscription activés, les données ont été transférées par une infrastructure tierce sans normes de sécurité spécifiques à l’industrie alimentaire, sans protections contractuelles de confidentialité, et sans audit SOC 2 pour vérifier comment ces données sont traitées.
Comment le créateur d’étiquettes alimentaires garde les recettes privées et sécurisées
Food Label Maker fonctionne sur une infrastructure privée auditée SOC 2 Type II — ce qui signifie que les contrôles de sécurité de la plateforme sont vérifiés de manière indépendante selon une norme reconnue. Les données de recettes, les formulations d’ingrédients et les informations sur les fournisseurs saisies sur la plateforme ne sont pas utilisées pour la formation des modèles, ne sont pas partagées avec des tiers et demeurent la propriété exclusive de l’entreprise alimentaire qui les a saisies.
Pour les fabricants alimentaires, les fabricants sous contrat et les entreprises multi-sites, cette distinction est importante. L’obtention du SOC 2 Type II n’est pas une réclamation autoévaluée — elle nécessite un audit indépendant de la manière dont les données sont accédées, stockées et protégées au fil du temps. C’est la même norme appliquée dans les logiciels bancaires et de santé, et elle offre l’assurance contractuelle et opérationnelle qu’un outil public d’IA ne peut offrir.
Conclusion : Faites confiance au générateur d’étiquettes nutritionnelles conçu pour la conformité
L’IA s’est imposée dans l’industrie alimentaire moderne en rédigeant des textes, en réfléchissant à des idées de produits, en résumant des recherches et en accélérant les tâches routinières. Mais l’étiquetage nutritionnel n’est pas une tâche routinière. C’est une obligation légale avec des spécifications mesurables et applicables, et les conséquences d’une erreur vont de reformulations coûteuses à des lettres d’avertissement et des rappels de produits.
Chaque grand modèle d’IA est un moteur de prédiction de séquences conçu pour estimer la sortie la plus probable, et non pour appliquer des règles sans exception. Cette distinction devient une responsabilité directe en conformité lorsque la tâche exige des tailles exactes de police, des poids de bordure précis, des valeurs quotidiennes correctes pour plusieurs marchés, une trace d’audit vérifiée et l’assurance que les formulations propriétaires ne quittent jamais un environnement sécurisé.
Les logiciels conçus spécialement existent parce que certains problèmes nécessitent des réponses déterministes, pas des suppositions éclairées. Food Label Maker repose sur ce principe avec des modèles verrouillés par la réglementation, des calculs déterministes, une gestion centralisée des recettes et une sécurité des données auditée de façon indépendante. Non pas parce que l’IA est une mauvaise technologie, mais parce que la conformité est un domaine où « assez proche » n’a jamais été suffisant.
Questions fréquemment posées
1. ChatGPT peut-il créer des étiquettes nutritionnelles conformes?
Bien que des outils d’IA comme ChatGPT puissent générer un texte ressemblant à une étiquette nutritionnelle, ils ne sont pas conçus pour répondre aux exigences légales précises imposées par les règlements d’étiquetage alimentaire. Les LLM génèrent des résultats basés sur des schémas statistiques plutôt que sur la logique réglementaire, ce qui signifie que les tailles de police, les poids des bordures, les règles d’arrondi et les mises en page bilingues peuvent varier entre les sorties et ne pas être conformes à ce que des organismes comme la FDA, l’ACIA, la FSA et l’UE exigent.
Pour les entreprises alimentaires opérant dans des marchés réglementés, la recommandation est d’utiliser un logiciel d’étiquetage nutritionnel spécialement conçu, conçu et mis à jour spécifiquement autour des exigences de conformité. Un générateur d’étiquettes nutritionnelles dédié applique exactement les bonnes règles, à chaque fois, ce qu’un outil d’IA polyvalent n’est pas conçu pour faire.
Si vous souhaitez commencer, créez une étiquette gratuite dès maintenant ou contactez notre équipe d’experts pour plus d’informations.
2. L’IA est-elle assez précise pour l’étiquetage des aliments?
Pour la plupart des tâches quotidiennes, l’IA est suffisamment précise. Mais l’étiquetage des aliments relève de la même catégorie à enjeux élevés que les informations juridiques et médicales. Ces domaines ont des recherches montrant que les taux d’hallucinations atteignent jusqu’à 6,4% même parmi les modèles les plus performants. Cela signifie que les outils d’IA les plus performants disponibles aujourd’hui produisent encore des informations fabriquées ou incorrectes environ 1 réponse sur 16 lorsque la tâche implique des informations précises et limitées par des règles.
Pour l’étiquetage alimentaire, où une seule inexactitude peut déclencher une lettre d’avertissement des organismes de réglementation, un rappel de produit ou un audit de détaillant raté, ce taux d’erreur n’est pas un risque acceptable. La conformité exige un outil qui applique les bonnes règles à chaque fois, et pas un outil qui les fait bien la plupart du temps.
Pour créer des étiquettes nutritionnelles conformes, commencez ici.
3. Qu’est-ce qu’un générateur d’étiquettes de données nutritionnelles?
Un générateur d’étiquettes de faits nutritionnels est un logiciel spécialement conçu qui calcule les valeurs nutritionnelles à partir des données d’ingrédients à l’aide de formules fixes et codées, puis produit les étiquettes dans des formats conformes aux réglementations spécifiques d’un marché donné, que ce soit la FDA aux États-Unis, la CFIA au Canada, le COFEPRIS au Mexique, la FSA au Royaume-Uni ou les normes de l’UE à travers l’Europe.
Contrairement à un outil d’IA à usage général, un générateur d’étiquettes de faits nutritionnels ne prédit pas à quoi une étiquette devrait ressembler en se basant sur des motifs. Au lieu de cela, elle applique des règles exactes à partir des tailles de police correctes, des poids de bordure, de la logique d’arrondi et des valeurs quotidiennes aux exigences bilingues pour chaque marché. Une plateforme d’étiquetage nutritionnel réglementaire, comme Food Label Maker, génère toujours de la même façon, peu importe qui l’utilise ou la formulation de la recette.
Découvrez ici le logiciel gratuit de générateur d’étiquettes nutritionnelles Food Label Maker.
4. En quoi le fabricant d’étiquettes alimentaires diffère-t-il de l’utilisation de l’IA pour les labels nutritionnels?
La différence fondamentale est que Food Label Maker est conçu spécialement pour la conformité réglementaire en matière d’étiquetage nutritionnel, tandis que l’IA est un outil polyvalent qui n’a jamais été conçu pour cela.
Food Label Maker applique des modèles d’étiquettes verrouillés par la réglementation pour la FDA, l’ACIA, la FSA, l’UE et d’autres marchés, ce qui signifie que chaque taille de police, poids de bordure, règle d’arrondi et exigence bilingue est codée en dur selon la norme réglementaire actuelle, et non estimée à partir des données d’entraînement. Les calculs de rendement et de perte d’humidité sont intégrés au flux de travail standard de la recette, donc la densité des nutriments est toujours basée sur le poids du produit fini plutôt que sur le total des ingrédients bruts. Toutes les recettes et ingrédients sont stockés dans une base de données centralisée, donc une mise à jour d’un seul ingrédient se propage automatiquement à chaque recette qui l’utilise. Les labels sont exportés sous forme de fichiers haute résolution prêts à l’impression à la résolution d’emballage et de production. Et chaque modification apportée à la plateforme est enregistrée avec un horodatage et une attribution utilisateur, créant ainsi une piste d’audit vérifiable.
Les outils de clavardage IA fonctionnent sans aucune de ces caractéristiques structurelles. Il n’y a pas de mémoire persistante entre les sessions, pas de formatage verrouillé par la réglementation, pas d’indication automatique de rendement, et aucun historique d’audit. Pour les tâches routinières, c’est correct. Pour produire une étiquette qui doit respecter une norme légale, il n’est pas recommandé.
En savoir plus sur la création d’étiquettes nutritionnelles conformes pour les 8 grands marchés mondiaux.
5. L’IA tient-elle compte de la perte d’humidité lors du calcul des informations nutritionnelles?
Pas automatiquement. Comme l’IA n’a pas de flux de travail intégré pour les recettes, elle ne calcule que ce que l’utilisateur demande explicitement. Un propriétaire d’entreprise alimentaire qui ne sait pas déjà qu’il doit demander le rendement recevra une étiquette calculée selon le poids des ingrédients bruts plutôt que le poids du produit fini. Il est aussi peu probable qu’ils reçoivent un avertissement de l’outil indiquant qu’il manque quelque chose.
Cela est important parce que la cuisson, la cuisson et la déshydratation réduisent le poids du produit fini par rapport aux ingrédients bruts, ce qui affecte directement la densité des nutriments par portion. Des recherches évaluant les LLM pour l’estimation du contenu nutritionnel ont révélé que l’IA a du mal à estimer avec précision le poids des aliments et la composition des nutriments, ce qui rend un calcul fiable du rendement improbable sans intervention explicite des utilisateurs.
Food Label Maker demande le rendement comme étape standard dans le flux de travail de la recette et calcule la densité des nutriments en fonction du poids du produit fini à l’aide de formules fixes et codées. Créez une étiquette gratuite dès aujourd’hui.
6. Est-il sécuritaire de coller des recettes dans ChatGPT?
Pour les entreprises utilisant des comptes consommateurs standards, il existe un risque de confidentialité des données qui mérite d’être compris. Selon les politiques de confidentialité publiées par OpenAI, Google et Anthropic, le contenu soumis via des comptes standards peut être utilisé pour améliorer et entraîner leurs modèles, à moins que l’utilisateur ne se retire activement ou détienne une entente de niveau entreprise.
Pour les entreprises alimentaires, cela signifie qu’une formulation propriétaire, un ratio d’ingrédients personnalisé ou un processus de fabrication unique entré dans une invite de clavardage n’est plus exclusivement privé. Même avec les paramètres de désinscription activés, les données sont passées par une infrastructure tierce sans protection de confidentialité spécifique à l’industrie alimentaire.
Food Label Maker fonctionne sur une infrastructure auditée SOC 2 Type II, ce qui signifie que les données de recettes, les formulations d’ingrédients et les informations sur les fournisseurs saisies dans la plateforme restent la propriété exclusive de l’entreprise qui y est entrée et ne sont jamais utilisés pour la formation de modèles.
Créez votre première étiquette gratuite, en toute sécurité.
7. Quelles réglementations le fabricant d’étiquettes alimentaires soutient-il?
Food Label Maker soutient les réglementations sur l’étiquetage nutritionnel dans huit grands marchés mondiaux :
- États-Unis — FDA, incluant tous les formats d’étiquettes standard, les vérifications RACC et les déclarations d’allergènes
- Canada — CFIA, incluant les exigences bilingues anglais/français et les étiquettes Front-of-Package (FOP)
- Royaume-Uni — FSA, incluant des formats obligatoires à l’arrière du paquet et aux feux de circulation
- Union européenne — DG SANTE, couvrant les 27 États membres
- Australie et Nouvelle-Zélande — FSANZ, qui couvre la conformité pour les deux pays au Code des normes alimentaires, incluant les exigences des panels d’information nutritionnelle, les déclarations d’allergènes et l’étiquetage du pays d’origine.
- Mexique — COFEPRIS, incluant des étiquettes d’avertissement frontales obligatoires et des formats bilingues
- Conseil de coopération du Golfe — GSO, incluant l’arabe et les formats d’étiquettes bilingues
Le format d’étiquette de chaque marché, ses valeurs quotidiennes, les règles d’arrondi, les exigences bilingues et les spécifications visuelles sont pré-codés sur la plateforme et mis à jour au fur et à mesure que les règlements changent.
Créez ici une étiquette nutritionnelle gratuite pour n’importe quelle grande région.
8. Que signifient les hallucinations dans les grands modèles de langage (LLM)?
Dans le contexte de l’IA, une hallucination fait référence au fait qu’un modèle génère une information qui semble plausible mais factuellement incorrecte ou entièrement fabriquée, et la présente avec la même confiance qu’une information exacte.
Cela arrive à cause de la façon dont les LLM sont fondamentalement construits. Comme établi plus tôt dans cet article, des modèles comme ChatGPT, Gemini et Claude sont des moteurs de prédiction de séquences qui génèrent des résultats en calculant la réponse la plus probable statistiquement basée sur des motifs dans leurs données d’entraînement. Lorsqu’un modèle rencontre une lacune dans ses connaissances, plutôt que de signaler de l’incertitude, il comble ce vide avec ce qui correspond statistiquement, qui peut n’avoir aucun fondement factuel.
Dans le contexte de l’étiquetage nutritionnel, les hallucinations peuvent se manifester par des valeurs nutritives incorrectes, des seuils réglementaires fabriqués, des règles d’arrondi qui n’existent pas, ou un format qui semble conforme mais ne l’est pas. Le risque particulier est que ces erreurs ne sont pas signalées. Le résultat ressemble et se lit comme une étiquette correcte, ce qui les rend faciles à manquer sans vérification manuelle selon la norme réglementaire réelle.
Prêt à créer une étiquette nutritionnelle entièrement conforme? Commencez ici.


